

May 6th 1949 is considered the birthday of modern computing as on this day, Maurice Wilkes and a team at Cambridge University executed the first stored-program on the EDSAC (Electronic Delay Storage Automatic Computer). Then on, scientists and engineers the world over made significant advances in the world of computing with the introduction of transistors, microprocessors and storage devices. However, computing large amounts of data was expensive and only prestigious universities, and big technology companies could afford to do so. The proof of concept and advocacy needed to persuade that machine intelligence was worth pursuing came in 1956 at the Dartmouth Summer Research Project on Artificial Intelligence (DSRPAI) hosted by John McCarthy and Marvin Minsky.
From 1957 to 1974 AI flourished with computers becoming cheaper and more accessible and machine learning algorithms improved with a better understanding of where to apply them. From the 1980s onwards with significant funding, innovation and superior technology, Artificial Intelligence achieved many of its landmark goals and continues to do so. In recent years, AI has made its way to practically every segment of human life, from marketing, banking, entertainment to healthcare and self-driving cars. It has saved countless human hours and increased human productivity. For example, in healthcare AI has empowered doctors to make better decisions and also helped in reducing human errors resulting in saving human lives.
One of the successful use cases of AI is in cancer detection, where it is used to assist the radiologist in not only detecting the tumour but also to identify its type. For example, a tumour wrongly classified can not only increase the treatment time but may also result in death, if not corrected at the right time. AI is also being used to distinguish between a benign tumour and an actual tumour. This helps in reducing the psychological trauma the patient has to go through in case of false positives. Recently, AI was also used to detect SARS COVID-19 (coronavirus) using CT scan with a 90.8% accuracy, which again is a noble example of how we can use AI-assisted healthcare to provide better health outcomes.
Although AI algorithms are becoming increasingly adept at producing results that are acceptable to humans, we have not, as of yet, been able to convincingly explain the inner workings of the model which lead to the desired results. Unlike conventional software algorithms which are mostly rule-based, AI algorithms are learning-based. This means humans have a control on what the input is and how the output should be. But since the algorithm itself is a set of probabilities and real numbers of features, it is nothing less than an opaque system whose working is not explainable in simple terms to an end-user. Hence AI models are increasingly being referred to as a “Black Box”.
Black Box in AI implies a system whose inputs and operations are not visible to the user or any party. Black Box models are created directly from data by an algorithm, and the people who design them mostly cannot understand how variables are being combined to make predictions. Explainable AI models, on the other hand, provide a technically equivalent, but an interpretable alternative to black box models. These models are constrained to give a better understanding of how predictions are made.
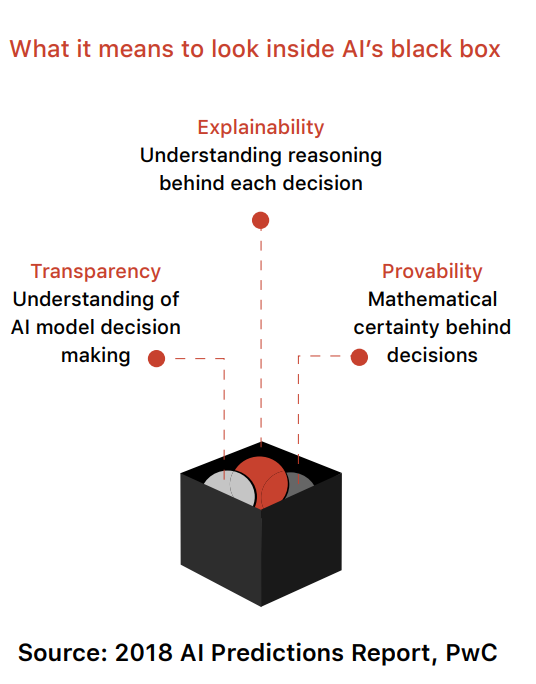
One reason why the black-box nature of the AI models is a critical point to be discussed is the Amazon recruitment example, where the AI unfairly discriminated against women as well as people of colour. And when things are serious, there is no way to know what did go wrong, and more importantly, what caused it to go wrong. In the US, risk assessment tools are designed to give every convict a recidivism score which is then used by a judge to decide whether a person can be granted parole. The data used to train the models that give the recidivism score are trained on historical data, which often disproportionately targets people of lower socio-economic strata, furthering this class drift.
In the past few years, advances in deep learning for computer vision have led to a common belief that the solution to any given data science problem should be inherently uninterpretable and complicated for reaching high accuracy. This belief stems from the historical use of machine learning in society, which are low-stakes decisions such as online advertising and web search, where individual choices do not profoundly affect human lives. But when AI enters a decisive part of human life, such as in healthcare or agriculture, we might ask how this decision came into being, which gives rise to the demand of Explainable AI. As the noise around AI applications in agriculture increases, probably faster than the models themselves, there are groups already working on building AI ethics frameworks. But in our opinion, the AI explainability paradigm needs to be overcome before venturing into making the ethics part of it for farmers.
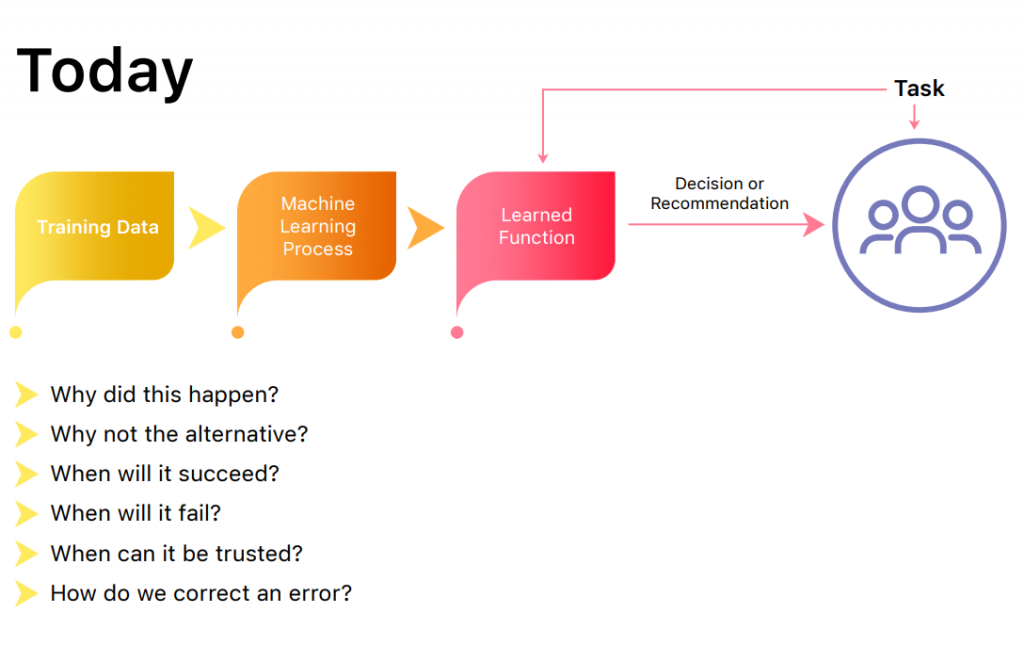
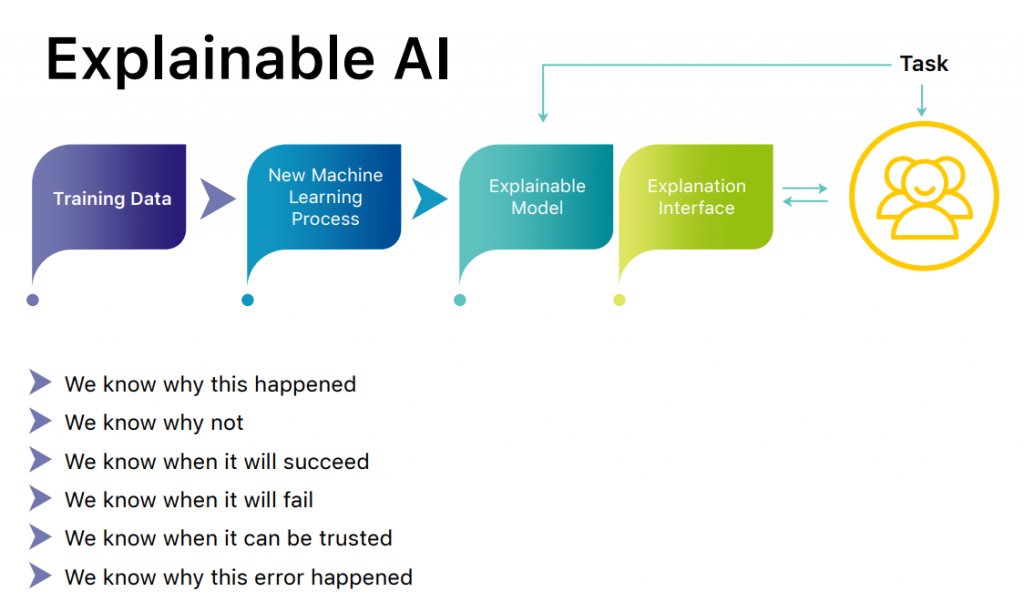
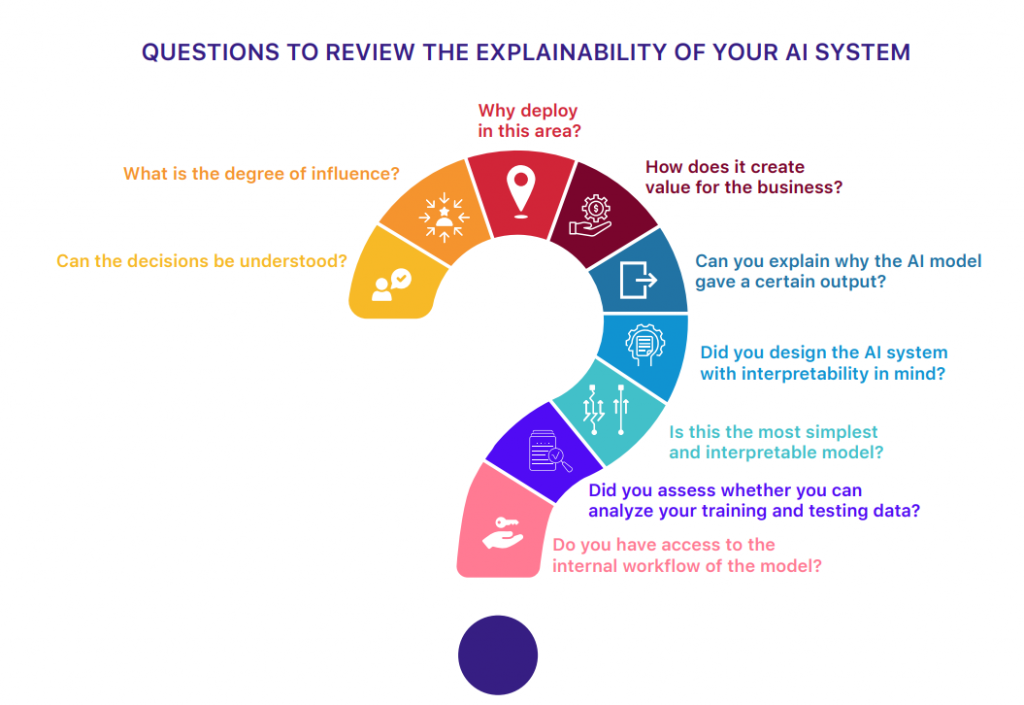
Adapted from: https://www.darpa.mil/program/explainable-artificial-intelligence
The societal implications of applying AI models for farmer and food quality related applications made us look into three different schools of thought emerging on how we can approach the problem of black box AI.
- PRE-MODELLING EXPLAINABILITY
The explainability at this stage is based on the knowledge of the data scientist. The assumption is that the data scientist understands the problem statement completely and will select a model that best suits the problem. Exploratory data analysis is used to understand the data and data distribution, which helps weed out any skew in the distribution, which often leads to a biased AI model. It is also at this stage that a walk-through of all the available methodologies to approach the given problem statement is done to explain which model understands the data characteristics better keeping in mind the ‘No Free Lunch’ theorem. The selection of the model should be based on domain knowledge with a consideration of each distinct feature representation.
- MODELLING EXPLAINABILITY
During the modelling phase, explainability can be achieved in two ways.
- First, we could use inherently explainable models, which often come at the cost of the model’s performance.
- Secondly, we could develop models by considering a trade-off between explainability and performance and optimising these in an acceptable way, using hybrid models. In this approach, models consisting of robust and explainable features are used during the training phase, followed by high-performance features during the validation phase.
A comprehensive way to evaluate model explainability is using a ‘human-in-the-loop’ approach. Here, the explainability is reviewed by a human and based on the decision, an explanation is either rewarded or penalised (reinforced). The limitation here is the human bias and consistency in their line of thought, which can often be visible in the input data itself; hence a board of reviewers is recommended.
- POST-MODELLING EXPLAINABILITY
Post modelling explainability is, by far the most explored and tested methodology. It gives the need for explainability but arose much later than the need for better performing models. This approach takes into account four key aspects of modelling: the output, estimator, cause and the explainability metric.
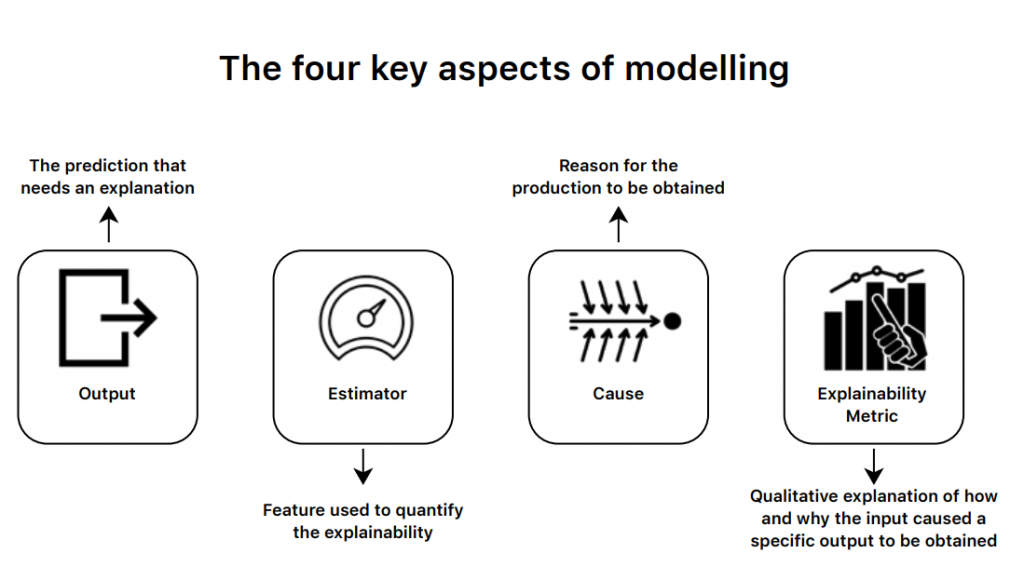
The Road Ahead for Explainable AI
Over the past few years, several R&D tools around explainable AI has gained momentum. However, there is still a large amount of apathy towards accepting AI due to the lack of convincing explainability. And before we indulge in the dream of AI replacing humans in sectors like agriculture and healthcare, our understanding of the models itself needs to develop to the extent where we can convince the consumer of the model’s output. This, in turn, would require a framework to be put in place.
The data scientists would list the features and quantitative explanations of the model along with human acceptability of the same from their side. Post which, the question of ethics arises as the output may be explainable but built on decades of biased data collection, and hence a similar framework is also to be agreed upon with the consumer whom the AI’s decision would directly or indirectly affect. As we can see, this is going to be a long drawn process of individuals debating and discussing before reaching an apt conclusion!
Written by Sanjutha Indrajit, Data Scientist, SatSure and Chinmay Shah, Junior Back-End Developer, SatSure. This article was originally published in The SatSure Newsletter.



Add comment